
Если вы хотите сериализовать и десериализовать объекты Python, вы, возможно, рассмотрите возможность использования модуля Python Pickle.
Модуль Python Pickle позволяет сериализовать и десериализовать структуру объекта Python. Pickle предоставляет две функции для записи/чтения в/из файловых объектов (dump() и load()). Он также предоставляет две функции для записи/чтения в/из байтовых объектов.
Мы рассмотрим несколько примеров, чтобы показать, как pickle работает как с файловыми объектами, так и с байтовыми объектами. Мы также протестируем его с несколькими типами данных.
Пришло время мариновать!
Пример Python Pickle
Модуль Python Pickle используется для сериализации и десериализации объектов Python.
Сериализация объекта Python означает его преобразование в поток байтов, который может быть сохранен в файле или в строке. Затем консервированные данные могут быть прочитаны с помощью процесса, называемого десериализацией.
Для сохранения консервированного объекта в строку используйте функцию dumps(). Для чтения объекта из строки, содержащей его консервированное представление, используйте функцию loads().
Давайте рассмотрим пример того, как можно использовать модуль pickle для сериализации списка Python.
>>> import pickle
>>> animals = ['tiger', 'lion', 'giraffe']
>>> pickle.dumps(animals) b'\x80\x04\x95\x1e\x00\x00\x00\x00\x00\x00\x00]\x94(\x8c\x05tiger\x94\x8c\x04lion\x94\x8c\x07giraffe\x94e.'После импорта модуля pickle мы определяем список, а затем используем функцию pickle dumps() для генерации байтового представления нашего списка.
Теперь мы сохраним обработанную строку в переменной и воспользуемся функцией loads(), чтобы преобразовать строку байтов обратно в наш исходный список.
>>> pickled_animals = pickle.dumps(animals)
>>> unpickled_animals = pickle.loads(pickled_animals)
>>> print(unpickled_animals)
['tiger', 'lion', 'giraffe']Буква s в конце функций pickle dumps() и loads() обозначает строку. Модуль pickle также предоставляет две функции, которые используют файлы для хранения и чтения консервированных данных: dump() и load().
Сохраните словарь Python с помощью Pickle
С помощью модуля pickle вы можете сохранять различные типы объектов Python.
Давайте воспользуемся функцией dumps() для консервирования словаря Python.
>>> animals = {'tiger': 23, 'lion': 45, 'giraffe': 67}
>>> pickled_animals = pickle.dumps(animals)
>>> print(pickled_animals)
b'\x80\x04\x95$\x00\x00\x00\x00\x00\x00\x00}\x94(\x8c\x05tiger\x94K\x17\x8c\x04lion\x94K-\x8c\x07giraffe\x94KCu.' А затем функция loads() возвращает словарь из его законсервированного представления.
>>> new_animals = pickle.loads(pickled_animals)
>>> print(new_animals)
>>> {'tiger': 23, 'lion': 45, 'giraffe': 67} Итак, это подтверждает, что мы также можем сохранять объекты словаря в строку байтов с помощью Pickle.
Записать словарь Pickled Python в файл
Модуль pickle также позволяет сохранять консервированное представление объекта Python в файле.
Для сохранения pickled объекта в файл используйте функцию dump(). Для чтения объекта из его маринованного представления, сохраненного в файле, используйте функцию load().
Сначала мы откроем файл в двоичном режиме с помощью функции Python open, сохраним словарь в файле и закроем файл.
>>> import pickle
>>> animals = {'tiger': 23, 'lion': 45, 'giraffe': 67}
>>> f = open('data.pickle', 'wb')
>>> pickle.dump(animals, f)
>>> f.close()Файл data.pickle будет создан в том же каталоге, что и ваша программа Python.
Примечание: не забудьте закрыть файл, когда закончите работу с ним.
Если вы посмотрите содержимое файла data.pickle с помощью текстового редактора, вы увидите данные в двоичном формате.
€•$ }”(Œtiger”KŒlion”K-Œgiraffe”KCu.Теперь считайте байты из файла и получите исходный объект словаря с помощью функции load().
>>> f = open('data.pickle', 'rb')
>>> unpickled_animals = pickle.load(f)
>>> f.close()
>>> print(unpickled_animals)
{'tiger': 23, 'lion': 45, 'giraffe': 67} На этот раз мы открыли файл в режиме чтения двоичных данных, поскольку хотим только прочитать его содержимое.
В следующем разделе мы увидим, может ли модуль pickle также сериализовать вложенные объекты.
Pickle — вложенный объект словаря
Давайте выясним, можно ли сериализовать и десериализовать вложенный словарь Python с помощью модуля Pickle.
Обновите словарь, использованный в предыдущем разделе, включив в него словари в качестве значений, сопоставленных каждому ключу.
>>> animals = {'tiger': {'count': 23}, 'lion': {'count': 45}, 'giraffe': {'count': 67}} Записать вложенный словарь в файл. Код идентичен тому, который мы видели ранее для консервирования базового словаря.
>>> f = open('data.pickle', 'wb')
>>> pickle.dump(animals, f)
>>> f.close()Пока ошибок нет…
Теперь преобразуем консервированные данные обратно во вложенный словарь:
>>> f = open('data.pickle', 'rb')
>>> unpickled_animals = pickle.load(f)
>>> f.close()
>>> print(unpickled_animals)
{'tiger': {'count': 23}, 'lion': {'count': 45}, 'giraffe': {'count': 67}} Вложенный словарь выглядит хорошо.
Использование Pickle с пользовательским классом
Я хочу узнать, смогу ли я создать пользовательский класс Python…
Давайте создадим класс под названием Animal, содержащий два атрибута.
class Animal:
def __init__(self, name, group):
self.name = name
self.group = groupЗатем создайте один объект и сохраните его в файле.
tiger = Animal('tiger', 'mammals')
f = open('data.pickle', 'wb')
pickle.dump(tiger, f)
f.close()И наконец, считайте данные с помощью функции pickle load().
f = open('data.pickle', 'rb')
data = pickle.load(f)
print(data)
f.close()Вот содержимое объекта данных:
<main.Animal object at 0x0353BF58>А вот атрибуты нашего объекта… как видите, они верны.
>>> print(data.__dict__)
{'name': 'tiger', 'group': 'mammals'} Вы можете настроить этот вывод, добавив метод __str__ в класс.
Сохранение нескольких объектов с помощью Pickle
Используя тот же класс, который определен в предыдущем разделе, мы сохраним два объекта в файле с помощью модуля pickle.
Создайте два объекта типа Animal и сохраните их в файле как список объектов:
tiger = Animal('tiger', 'mammals')
crocodile = Animal('crocodile', 'reptiles')
f = open('data.pickle', 'wb')
pickle.dump([tiger, crocodile], f)
f.close()Доступ к каждому объекту можно получить с помощью цикла for.
f = open('data.pickle', 'rb')
data = pickle.load(f)
f.close()
for animal in data:
print(animal.__dict__)
[output]
{'name': 'tiger', 'group': 'mammals'}
{'name': 'crocodile', 'group': 'reptiles'}Pickle и Python с заявлением
До сих пор нам приходилось помнить о необходимости закрывать файловый объект каждый раз после завершения работы с ним.
Вместо этого мы можем использовать оператор with open, который автоматически закроет файл.
Вот как будет выглядеть наш код для записи нескольких объектов:
tiger = Animal('tiger', 'mammals')
crocodile = Animal('crocodile', 'reptiles')
with open('data.pickle', 'wb') as f:
pickle.dump([tiger, crocodile], f) А теперь используйте оператор with open также для чтения консервированных данных…
with open('data.pickle', 'rb') as f:
data = pickle.load(f)
print(data)
[output]
[<__main__.Animal object at 0x7f98a015d2b0>, <__main__.Animal object at 0x7f98a01a4fd0>] Отлично, теперь гораздо лаконичнее.
Больше не нужно вызывать f.close() каждый раз при чтении или записи файла.
Использование Python Pickle с лямбдами
До сих пор мы использовали модуль pickle с переменными, но что произойдет, если мы используем его с функцией?
Определите простую лямбда-функцию, которая возвращает сумму двух чисел:
>>> import pickle
>>> pickle.dumps(lambda x,y: x+y)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
_pickle.PicklingError: Can't pickle <function <lambda> at 0x7fbc60296c10>: attribute lookup <lambda> on __main__ failedМодуль pickle не позволяет сериализовать лямбда-функцию.
В качестве альтернативы мы можем использовать модуль Dill, который расширяет функциональность модуля Pickle.
При попытке импортировать модуль Dill может возникнуть следующая ошибка…
>>> import dill
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ModuleNotFoundError: No module named 'dill' В этом случае вам придется установить модуль dill с помощью pip:
$ pip install dill
Collecting dill
Downloading dill-0.3.3-py2.py3-none-any.whl (81 kB)
|████████████████████████████████| 81 kB 4.4 MB/s
Installing collected packages: dill
Successfully installed dill-0.3.3 Модуль dill обеспечивает функции дампа и загрузки так же, как и модуль pickle.
Давайте сначала создадим объект bytes из лямбда-выражения, используя функцию dumps:
>>> import dill
>>> pickled_lambda = dill.dumps(lambda x,y: x+y)
>>> print(pickled_lambda) b'\x80\x04\x95\x9e\x00\x00\x00\x00\x00\x00\x00\x8c\ndill._dill\x94\x8c\x10_create_function\x94\x93\x94(h\x00\x8c\x0c_create_code\x94\x93\x94(K\x02K\x00K\x00K\x02K\x02KCC\x08|\x00|\x01\x17\x00S\x00\x94N\x85\x94)\x8c\x01x\x94\x8c\x01y\x94\x86\x94\x8c\x07<stdin>\x94\x8c\x08<lambda>\x94K\x01C\x00\x94))t\x94R\x94c__builtin__\n__main__\nh\x0bNN}\x94Nt\x94R\x94.' Затем распакуйте данные с помощью функции loads:
>>> print(dill.loads(pickled_lambda))
<function <lambda> at 0x7f9558408280>
>>> unpickled_lambda = dill.loads(pickled_lambda)
>>> unpickled_lambda(1,3)
4 Оно работает!
Лямбда-функция возвращает ожидаемый нами результат.
Ошибка при выборе класса с атрибутом Lambda
Давайте вернемся к пользовательскому классу, который мы определили ранее…
Мы уже видели, как сериализовать и десериализовать его. Теперь давайте добавим новый атрибут и установим его значение в лямбда-функцию.
class Animal:
def __init__(self, name, group):
self.name = name
self.group = group
self.description = lambda: print("The {} belongs to {}".format(self.name, self.group)) Примечание: этот атрибут лямбда не принимает никаких входных аргументов. Он просто выводит строку на основе значений двух других атрибутов экземпляра класса.
Во-первых, убедитесь, что класс работает нормально:
tiger = Animal('tiger', 'mammals')
tiger.description()
crocodile = Animal('crocodile', 'reptiles')
crocodile.description() Здесь вы можете увидеть вывод лямбда-функции:
$ python3 exclude_class_attribute.py
The tiger belongs to mammals
The crocodile belongs to reptilesВы знаете, что модуль pickle не может сериализовать лямбда-функцию. И вот что происходит, когда мы сериализуем наши два объекта, созданные из пользовательского класса.
Traceback (most recent call last):
File "multiple_objects.py", line 16, in <module>
pickle.dump([tiger, crocodile], f)
AttributeError: Can't pickle local object 'Animal.__init__.<locals>.<lambda>'Это вызвано атрибутом лямбда внутри наших двух объектов.
Исключить атрибут класса Python из Pickling
Есть ли способ исключить атрибут лямбда из процесса сериализации нашего пользовательского объекта?
Да, для этого мы можем использовать метод класса __getstate__().

Чтобы понять, что делает метод __getstate__, начнем с рассмотрения содержимого __dict__ для одного из экземпляров нашего класса.
tiger = Animal('tiger', 'mammals')
print(tiger.__dict__)
[output]
{'name': 'tiger', 'group': 'mammals', 'description': <function Animal.__init__.<locals>.<lambda> at 0x7fbc9028ca60>} Чтобы иметь возможность сериализовать этот объект с помощью pickle, нам нужно исключить атрибут lambda из процесса сериализации.
Чтобы избежать сериализации лямбда-атрибута с помощью __getstate__(), мы сначала скопируем состояние нашего объекта из self.__dict__, а затем удалим атрибут, который не может быть преобразован.
class Animal:
def __init__(self, name, group):
self.name = name
self.group = group
self.description = lambda: print("The {} is a {}".format(self.name, self.group))
def __getstate__(self):
state = self.__dict__.copy()
del state['description']
return stateПримечание: мы используем метод dict.copy(), чтобы убедиться, что мы не изменим исходное состояние объекта.
Давайте посмотрим, сможем ли мы теперь замариновать этот объект…
tiger = Animal('tiger', 'mammals')
pickled_tiger = pickle.dumps(tiger)Прежде чем продолжить, убедитесь, что интерпретатор Python не выдает никаких исключений при консервировании объекта.
Теперь распакуйте данные и проверьте значение __dict__.
unpickled_tiger = pickle.loads(pickled_tiger)
print(unpickled_tiger.__dict__)
[output]
{'name': 'tiger', 'group': 'mammals'}Сработало! И неконсервированный объект больше не содержит атрибута лямбда.
Восстановите исходную структуру объекта Python с помощью Pickle
Мы увидели, как исключить из процесса сериализации объекта Python один атрибут, для которого консервирование не поддерживается.
Но что, если мы хотим сохранить исходную структуру объекта в процессе консервирования/расконсервирования?
Как мы можем вернуть наш лямбда-атрибут после распаковки байтового представления нашего объекта?
Мы можем использовать метод __setstate__, который, как объясняется в официальной документации, вызывается с неконсервированным состоянием как часть процесса деконсервации.
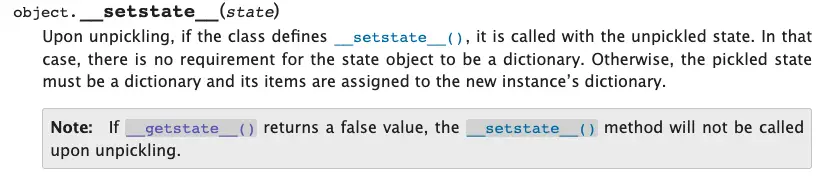
Обновите наш класс, чтобы реализовать метод __setstate__(). Этот метод восстановит атрибуты экземпляра, а затем добавит атрибут лямбда, который не был частью замаринованного объекта.
class Animal:
def __init__(self, name, group):
self.name = name
self.group = group
self.description = lambda: print("The {} is a {}".format(self.name, self.group))
def __getstate__(self):
state = self.__dict__.copy()
del state['description']
return state
def __setstate__(self, state):
self.__dict__.update(state)
self.description = lambda: print("The {} is a {}".format(self.name, self.group)) Давайте законсервируем и расконсервируем объект, чтобы убедиться, что мы получаем обратно атрибут лямбда.
tiger = Animal('tiger', 'mammals')
pickled_tiger = pickle.dumps(tiger)
unpickled_tiger = pickle.loads(pickled_tiger)
print(unpickled_tiger.__dict__)
[output]
{'name': 'tiger', 'group': 'mammals', 'description': <function Animal.__setstate__.<locals>.<lambda> at 0x7f9380253e50>} Все хорошо, неконсервированный объект также содержит атрибут лямбда.
Консервирование и деконсервирование между Python 2 и Python 3
Я хочу выяснить, существуют ли какие-либо ограничения при консервировании данных с помощью одной версии Python и их расконсервировании с помощью другой версии Python.
Существует ли обратная совместимость с модулем pickle между Python 2 и 3?
В этом тесте я буду использовать Python 3.8.5 для сериализации списка кортежей и Python 2.7.16 для его десериализации.
Python 3.8.5 (default, Sep 4 2020, 02:22:02)
[Clang 10.0.0 ]:: Anaconda, Inc. on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import pickle
>>> animals = [('tiger', 'mammals'), ('crocodile', 'reptiles')]
>>> with open('data.pickle', 'wb') as f:
... pickle.dump(animals, f)
...
>>> exit()Выйдите из оболочки Python, чтобы убедиться, что файл data.pickle создан.
$ ls -al data.pickle
-rw-r--r-- 1 myuser mygroup 61 3 May 12:01 data.pickle Теперь воспользуемся Python 2 для распаковки данных:
Python 2.7.16 (default, Dec 21 2020, 23:00:36)
[GCC Apple LLVM 12.0.0 (clang-1200.0.30.4) [+internal-os, ptrauth-isa=sign+stri on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import pickle
>>> with open('data.pickle', 'rb') as f:
... data = pickle.load(f)
...
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
File "/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/pickle.py", line 1384, in load
return Unpickler(file).load()
File "/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/pickle.py", line 864, in load
dispatch[key](self)
File "/System/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/pickle.py", line 892, in load_proto
raise ValueError, "unsupported pickle protocol: %d" % proto
ValueError: unsupported pickle protocol: 4Это не сработало, интерпретатор Python выдает исключение ValueError, сообщающее о том, что протокол pickle не поддерживается.
Давайте выясним, почему и о каком протоколе говорит переводчик…
Протокол по умолчанию для Python Pickle
Согласно документации модуля Pickle, для травления вашим интерпретатором Python используется версия протокола по умолчанию.
Значение DEFAULT_PROTOCOL зависит от используемой версии Python…
…хорошо, мы к чему-то приближаемся…

Похоже, что протокол по умолчанию для Python 3.8 — 4, это соответствует ошибке, которую мы видели, учитывая, что интерпретатор Python 2 жалуется на ошибку «неподдерживаемый протокол pickle: 4».
Используя оболочку Python, мы можем подтвердить значение параметра DEFAULT_PROTOCOL для нашего интерпретатора Python 3.
Python 3.8.5 (default, Sep 4 2020, 02:22:02)
[Clang 10.0.0 ]:: Anaconda, Inc. on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import pickle
>>> print(pickle.DEFAULT_PROTOCOL)
4Интересно, можно ли использовать интерпретатор Python 3.8.5 для генерации консервированных данных и указать версию протокола, поддерживаемую Python 2.7.16.
Протокол версии 3 был добавлен в Python 3.0, а протокол версии 2 был реализован в Python 2.3.
Таким образом, мы должны иметь возможность использовать версию 2 при консервировании нашего списка кортежей…
Мы можем передать протокол в качестве третьего аргумента функции pickle dump(), как вы можете видеть ниже:

Давайте попробуем…
>>> import pickle
>>> animals = [('tiger', 'mammals'), ('crocodile', 'reptiles')]
>>> with open('data.pickle', 'wb') as f:
... pickle.dump(animals, f, 2)
...
>>> А теперь давайте разберемся с этим с помощью Python 2:
Python 2.7.16 (default, Dec 21 2020, 23:00:36)
[GCC Apple LLVM 12.0.0 (clang-1200.0.30.4) [+internal-os, ptrauth-isa=sign+stri on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import pickle
>>> with open('data.pickle', 'rb') as f:
... data = pickle.load(f)
...
>>> print(data)
[(u'tiger', u'mammals'), (u'crocodile', u'reptiles')]Это сработало!
Итак, теперь вы знаете, как сохранять данные с помощью pickle, если вам необходимо обмениваться ими между приложениями, использующими разные версии Python.
You can get the highest protocol available for the pickle module used by your Python interpreter by looking at the value of pickle.HIGHEST_PROTOCOL. You can pass this value to the functions dump() and dumps().Сжатие данных, созданных с помощью Python Pickle
Если у вас есть большой объем данных для сохранения с помощью pickle, вы можете уменьшить размер ваших данных, применив к ним сжатие bzip2. Для этого вы можете использовать модуль Python bz2.
Модуль bz2 предоставляет класс bz2.BZ2File, который позволяет открывать файл, сжатый с помощью bzip2, в двоичном режиме.

Вот как мы можем использовать его со списком кортежей и вместе с pickle:
>>> import pickle
>>> import bz2
>>> animals = [('tiger', 'mammals'), ('crocodile', 'reptiles')]
>>> with bz2.BZ2File('data.pickle.compressed', 'w') as f:
... pickle.dump(animals, f)
...
>>>Мы можем использовать встроенную функцию Python type() для подтверждения типа нашего файлового объекта.
>>> type(f)
<class 'bz2.BZ2File'> А теперь давайте распакуем сжатые данные…
>>> with bz2.BZ2File('data.pickle.compressed', 'r') as f:
... print(pickle.load(f))
...
[('tiger', 'mammals'), ('crocodile', 'reptiles')] Хорошо 🙂
Python Pickle и Pandas DataFrames
Давайте выясним, можно ли использовать модуль pickle для сериализации и десериализации фрейма данных Pandas.
Сначала создайте новый фрейм данных:
>>> import pandas as pd
>>> df = pd.DataFrame({"Animals": ["Tiger", "Crocodile"], "Group": ["Mammals", "Reptiles"]})
>>> print(df)
Animals Group
0 Tiger Mammals
1 Crocodile Reptiles Можем ли мы сериализовать этот объект?
>>> import pickle
>>> pickled_dataframe = pickle.dumps(df) Да, мы можем!
Давайте посмотрим, сможем ли мы вернуть исходный фрейм данных с помощью функции pickle loads().
>>> unpickled_dataframe = pickle.loads(pickled_dataframe)
>>> print(unpickled_dataframe)
Animals Group
0 Tiger Mammals
1 Crocodile Reptiles Да, это так!
Библиотека Pandas также предоставляет собственные функции для консервирования и деконсервирования фрейма данных.
Вы можете использовать функцию to_pickle() для сериализации фрейма данных в файл:
>>> df.to_pickle('./dataframe.pickle') Это файл, содержащий консервированный фрейм данных:
$ ls -al dataframe.pickle
-rw-r--r-- 1 myuser mygroup 706 3 May 14:42 dataframe.pickle Чтобы получить обратно фрейм данных, можно использовать функцию read_pickle().
>>> import pandas as pd
>>> unpickled_dataframe = pd.read_pickle('./dataframe.pickle')
>>> print(unpickled_dataframe)
Animals Group
0 Tiger Mammals
1 Crocodile Reptiles Именно то, чего мы ожидали.
Безопасность Python Pickle
Все, что мы видели до сих пор о модуле Pickle, замечательно, но в то же время модуль Pickle небезопасен.
It's important to only unpickle data that you trust. Data for which you definitely know the source.
Почему?
Процесс десериализации Pickle небезопасен.
Консервированные данные можно сконструировать таким образом, чтобы при их расконсервации выполнялся произвольный код.
Консервированные данные могут действовать как эксплойт, используя метод __setstate__(), который мы видели в одном из предыдущих разделов, для добавления атрибута к нашему десериализованному объекту.
Вот базовый класс, который объясняет, как это будет работать:
import pickle, os
class InsecurePickle:
def __init__(self, name):
self.name = name
def __getstate__(self):
return self.__dict__
def __setstate__(self, state):
os.system('echo Executing malicious command')Как вы видите, в реализации метода __setstate__ мы можем вызвать любую произвольную команду, которая может нанести вред системе, распаковывающей данные.
Давайте посмотрим, что произойдет, если мы замаринуем и расконсервируем этот объект…
insecure1 = InsecurePickle('insecure1')
pickled_insecure1 = pickle.dumps(insecure1)
unpickled_insecure1 = pickle.loads(pickled_insecure1)Вот вывод этого кода:
$ python3 pickle_security.py
Executing malicious commandНапример, вы можете использовать вызов os.system для создания обратной оболочки и получения доступа к целевой системе.
Защита консервированных данных с помощью HMAC
Одним из способов защиты консервированных данных от несанкционированного доступа является наличие защищенного соединения между двумя сторонами, обменивающимися консервированными данными.
Также можно повысить безопасность данных, передаваемых между несколькими системами, с помощью криптографической подписи.
Идея заключается в следующем:
- Консервированные данные подписываются перед сохранением в файловой системе или перед передачей другому лицу.
- Затем его подпись может быть проверена до того, как данные будут расшифрованы.
Этот процесс может помочь понять, были ли подделаны сохраненные данные и, следовательно, их чтение может быть небезопасным.
Мы применим криптографическую подпись к фрейму данных Pandas, определенному перед использованием модуля Python hmac:
>>> import pandas as pd
>>> import pickle
>>> df = pd.DataFrame({"Animals": ["Tiger", "Crocodile"], "Group": ["Mammals", "Reptiles"]})
>>> pickled_dataframe = pickle.dumps(df) Предположим, что отправитель и получатель используют следующий секретный ключ:
secret_key = '25345-abc456'Отправитель генерирует дайджест данных с помощью функции hmac.new().
>>> import hmac, hashlib
>>> digest = hmac.new(secret_key.encode(), pickled_dataframe, hashlib.sha256).hexdigest()
>>> print(digest)
022396764cea8a60a492b391798e4155daedd99d794d15a4d574caa182bab6ba Получатель знает секретный ключ и может вычислить дайджест, чтобы подтвердить, совпадает ли его значение со значением, полученным с консервированными данными.
Если два значения дайджеста одинаковы, получатель знает, что сохраненные данные не были изменены и их можно безопасно прочитать.
Заключение
Если до прочтения этого руководства у вас не было возможности использовать модуль pickle, то теперь вы должны иметь довольно хорошее представление о том, как работает pickle.
Мы увидели, как использовать pickle для сериализации списков, словарей, вложенных словарей, списков кортежей, пользовательских классов и фреймов данных Pandas.
Вы также узнали, как исключить определенные атрибуты, которые не поддерживаются pickle, из процесса сериализации.
Наконец, мы рассмотрели проблемы безопасности, которые могут возникнуть при обмене данными, сериализованными с помощью pickle.
Теперь ваша очередь…
…как вы планируете использовать модуль pickle в своем приложении?